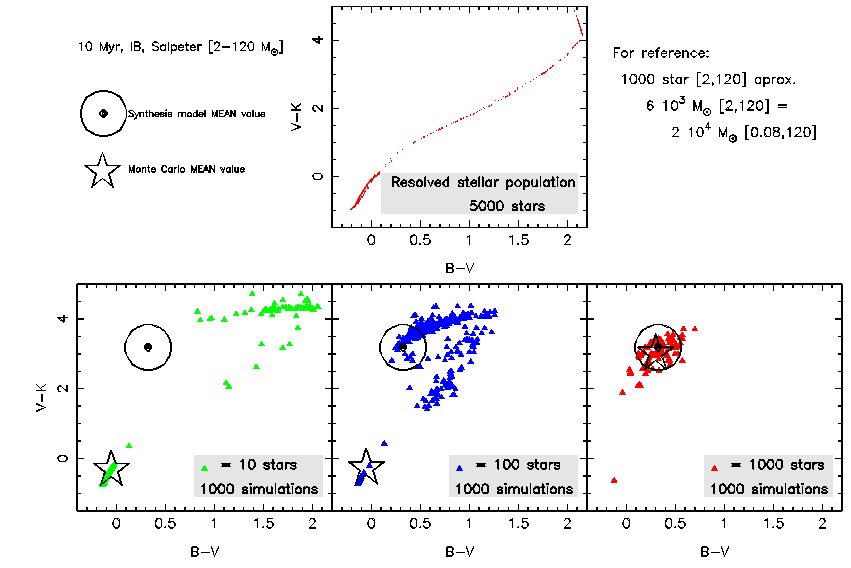
Covariance and Diagnostic Diagrams
For two quantities L1 and L2 it is possible to obtain
the covariance using:
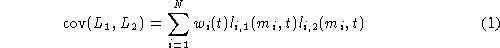
that is related with the correlation coefficient by:
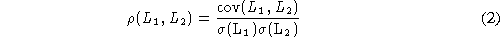
It can be also demonstrated that 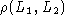 is
independent of the sampling. Then it is possible to obtain the
confidence levels of the diagnostic diagrams obtained by synthesis models
in function of the number of stars (or the mass into stars) in the modeled
star forming region.
is
independent of the sampling. Then it is possible to obtain the
confidence levels of the diagnostic diagrams obtained by synthesis models
in function of the number of stars (or the mass into stars) in the modeled
star forming region.
Note that it is necessary to take into account the
dispersion in both axes for the computation of the Confidence Interval in diagnostic
diagrams.
Gaussian distributions
In the case of Gaussian distributions, the ellipse:
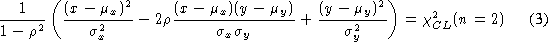
gives us the region covered by a Confidence Level CL (As reference,
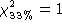 and
and 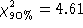 ). In the case that
). In the case that 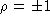 the ellipse becomes a straight line, and, in other cases, the ellipse is
tilted by an angle
the ellipse becomes a straight line, and, in other cases, the ellipse is
tilted by an angle  given by:
given by:
If 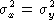 ,
, 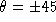 (deg) according with the
value of
(deg) according with the
value of 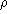 .
.
Note that will be always
the same whatever the number/mass of stars.
The ellipse semiaxes, a and b are given by:
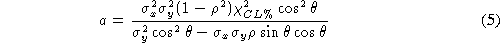
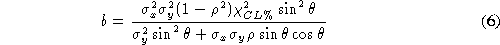
Different cases ares showed in the Figure:

Quasi-Poisson distributions
The absolute (denormalized) value of 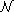 defines the mean value of a quasi-Poisson
distribution. In this case,
defines the mean value of a quasi-Poisson
distribution. In this case, 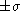 does NOT
correspond to
does NOT
correspond to 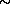 68% of the full height maximum (i.e. 68%
CL) of the underlying distribution, nor
68% of the full height maximum (i.e. 68%
CL) of the underlying distribution, nor 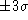 defines the 99% CL (that is the case of Gausanian distributions).
defines the 99% CL (that is the case of Gausanian distributions).
Note also that Gaussian distributions allow the
existence of negative values. This occurs when
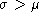 , but it has NO physical meaning
(number of stars, luminosities, intensities, etc... are positive defined
quantities) . Then, the Gaussian approximation certainly
will fail when
, but it has NO physical meaning
(number of stars, luminosities, intensities, etc... are positive defined
quantities) . Then, the Gaussian approximation certainly
will fail when 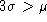 , i.e.
, i.e. 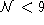
Even more, the underlying distributions are not
symmetric and may present different values for the upper
(CL+) and the lower (CL-) tails. Also, the region covered by the given CL will not be an
ellipse. However such region will be inside the
box delimited by 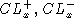 and
and 
So, only in the case of large values
(  ) the underlying distribution
can be approximated by a Gaussian one. To illusitrate this item we compare
in the figure the corresponding Gaussian ellipses with the boxes that
includes the 90% CL for Poisson distributions:
) the underlying distribution
can be approximated by a Gaussian one. To illusitrate this item we compare
in the figure the corresponding Gaussian ellipses with the boxes that
includes the 90% CL for Poisson distributions:

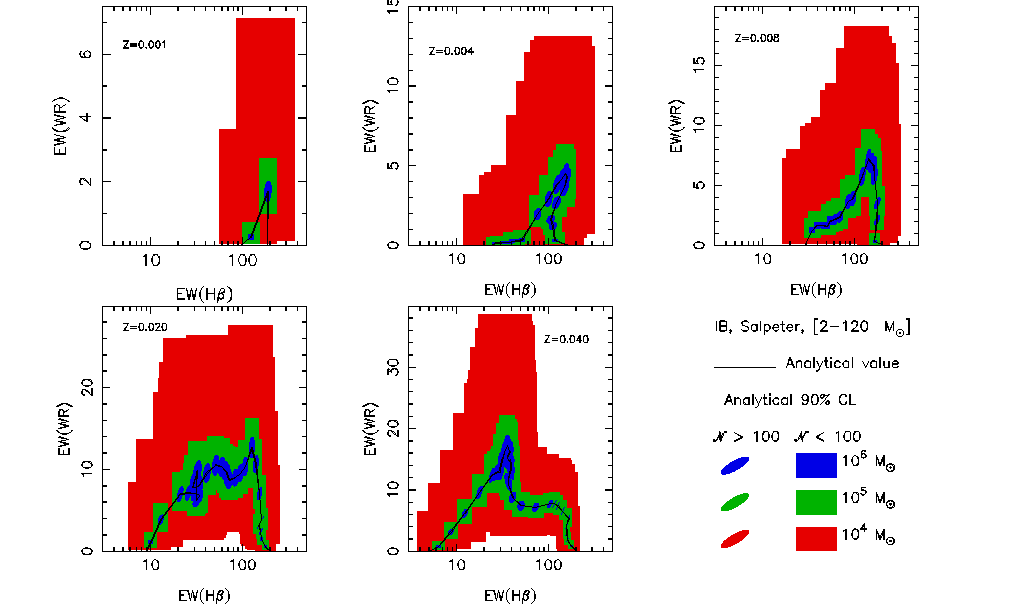
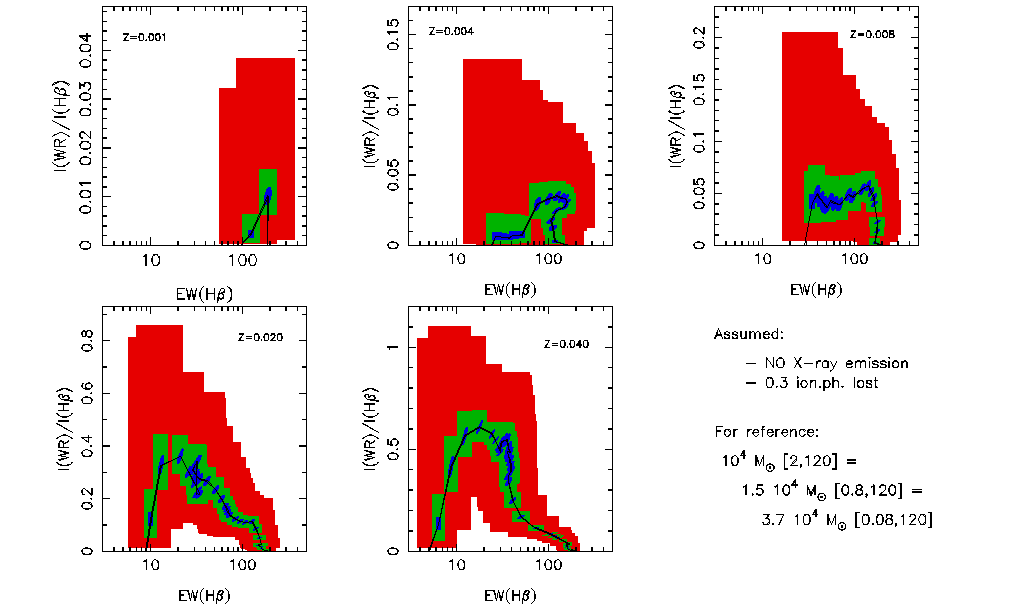
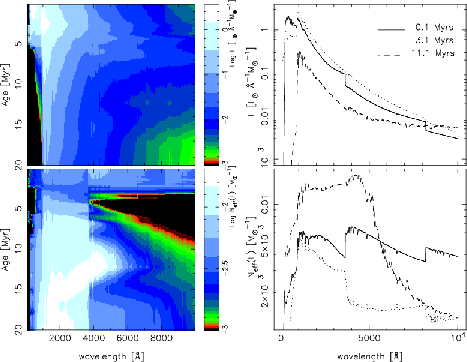
An example: Results for WR population
As an example, I show the results for the EW(WR bump) vs. EW(H  ) and I(WR
bump)/I(H ) vs. EW(H ) diagnostic diagrams in
the next figures.
A covering factor of 0.7 (i.e. 0.3 of the ionizing photons are lost) is
assumed to obtain the I(H ) emission line and the nebular
contribution to the continuum. The simulation does not include the X-ray
contribution. Figures make use of Geneva evolutionary
tracks with standard mass-loss rates (see astro-ph/0206169) (click in the
figure for a better resolution one).
) and I(WR
bump)/I(H ) vs. EW(H ) diagnostic diagrams in
the next figures.
A covering factor of 0.7 (i.e. 0.3 of the ionizing photons are lost) is
assumed to obtain the I(H ) emission line and the nebular
contribution to the continuum. The simulation does not include the X-ray
contribution. Figures make use of Geneva evolutionary
tracks with standard mass-loss rates (see astro-ph/0206169) (click in the
figure for a better resolution one).
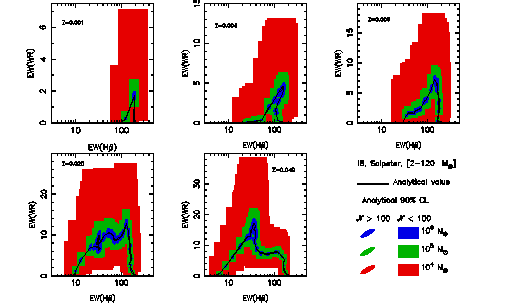
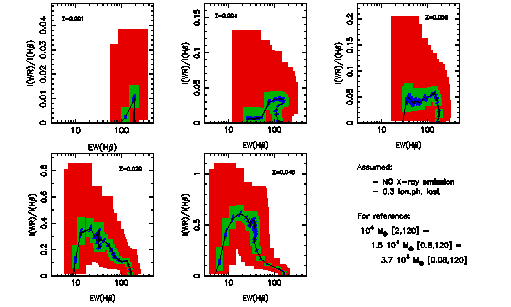
This figures can be compared with the results from Pindao,
Schaerer et al. (2002 A&A 394, 443) taken into account that the
WRbump here includes all the band and the one computed in that article are
only some selected lines in the band (i.e. here the bump is about a factor
3 larger). Comparing the figures you can evaluate how relevant the sampling
effects may be...
Bias
The final point to be addressed in this subject is the bias of the results of synthesis models respect to real observations. This bias in related with the
Lowest Luminosity Limit quoted before. For a more exaustive reading of the problem I refer to
Cerviño, & Valls-Gabaud, (2003 MNRAS 338, 481).
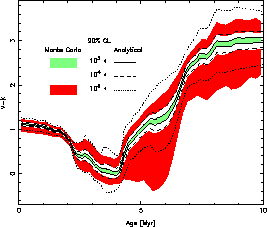
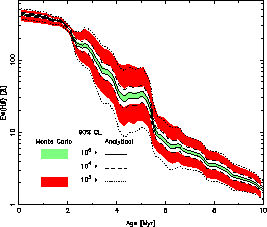
Let me began with with the work of Bruzual (2002;
astro-ph/0110245) who show the next figure:
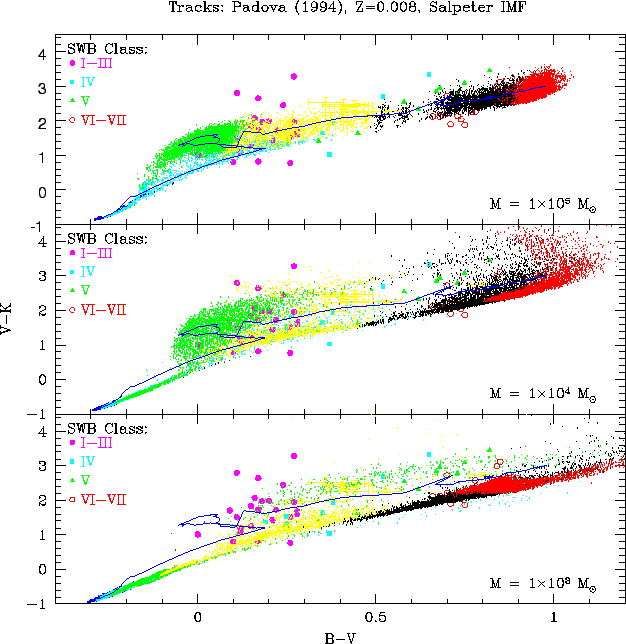
Here the big points corresponds to different clusters with SWB Class (a
class defined to stimate the age), the blue line
corresponds to the analytical (standard) result and the small dots
corresponds to Monte Carlo simulations for different amount of gas
transformed into stars (the color code, corresponds to different
ages). Note that different colors are overimposed (light
bule points are oculted y green points for
104Mo and 103Mo simulations and green points are oculted y yellow
points for 103Mo simulations etc..). In his paper he does
not talk about the bias of the results of the synthesis models obtained
from Monte Carlo simulations (where the number of stars is discrete) and
analytical simulations, but such a bias is clear in the figures.
The effect is quite important and general for ratios (like equivalent
widths), colors or log quantities. I refer again to Cerviño,
& Valls-Gabaud, (2003 MNRAS 338, 481) for a more detailled
explanation.

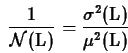
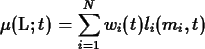
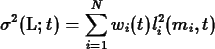
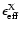 =20%
=20%